
Guide to Database Sharding and Partitioning Strategies
I was recently reading the chapter on partitioning in the book Designing Data-Intensive Applications. If you work on distributed systems that need to scale, I would definitely recommend reading this book.
This article is just to journal and summarize my learnings from this chapter on partitioning.
What is Sharding and Partitioning?
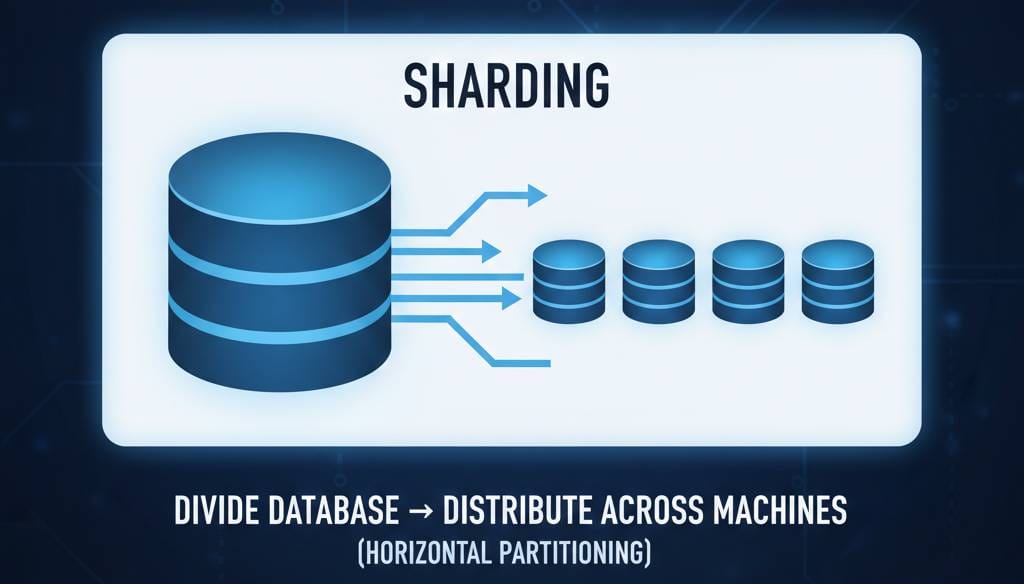
Sharding is a process of dividing a database into smaller batches and distributing them across multiple machines. Partitioning is how we divide that data into smaller batches to improve query efficiency. Although the terms are used interchangeably, sharding often refers to horizontal partitioning (split by rows instead of columns) across different machines.
But why do we do that? Well, the size of your database without sharding is limited by the size of your physical hard drive. When your database reaches that physical limit (i.e., 1TB, 2TB, etc.), you will encounter a problem. So instead of storing all this data on a single machine, we can distribute it across 10 machines, each handling it independently.
Sharding allows a larger number of users to access the database simultaneously. Instead of being limited by the read/write speed of one hard drive, we will be limited by the combined read/write speed of multiple hard drives.
It also distributes the risk of losing data across the drives. If the data were sitting on one drive, then we could have to rely only on the health of that drive. If it fails, we lose all the data. With a sharded database, if a drive fails, we will lose only the data in that one shard.
So how do we go about distributing this data? There are various partitioning techniques. Let’s have a look at those.
Partitioning Strategies
Random / Equal Partitioning
Given that we want to distribute data across the nodes, we could perform an equal split of the data and push it to different nodes. While this will solve our distribution problem, we will have a tough time finding a record during queries, as we would have no idea which partition it is present in.
Round Robin Partitioning
In round robin partitioning, we equally balance the shards by storing the next incoming record of data in the next available partition in the cycle.
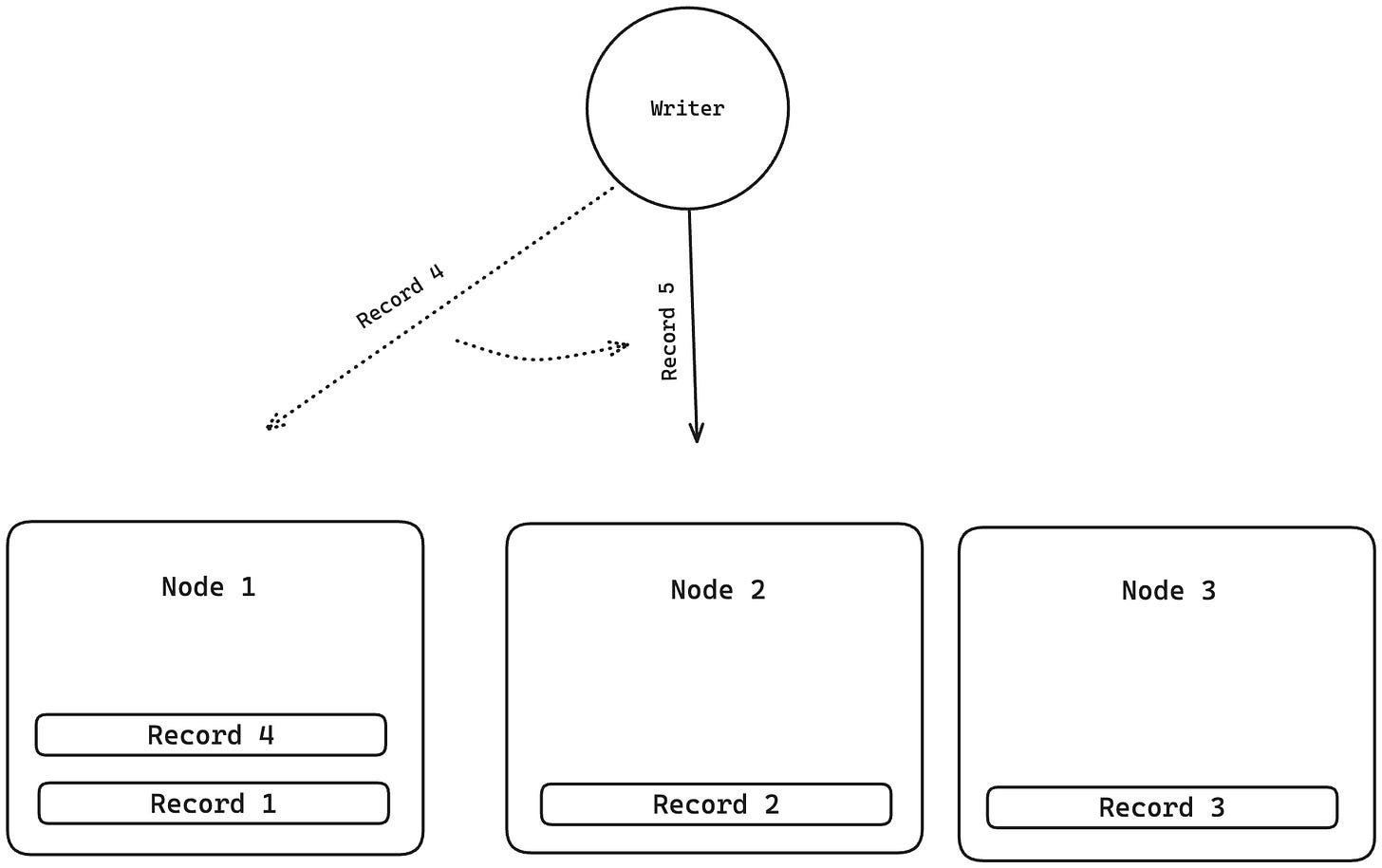
For example, if we have 3 nodes/shards and 4 records, then:
- Record 1 goes to partition 1
- Record 2 goes to partition 2
- Record 3 goes to partition 3
- Record 4 goes to partition 1
and so on. This way, all the shards have an equal amount of data. The issue with the approach is that while querying, the database has no idea on which shard the record it seeks lives on. It will have to make a scatter-gather query where all the nodes receive the request and start searching for the record.
List Partitioning
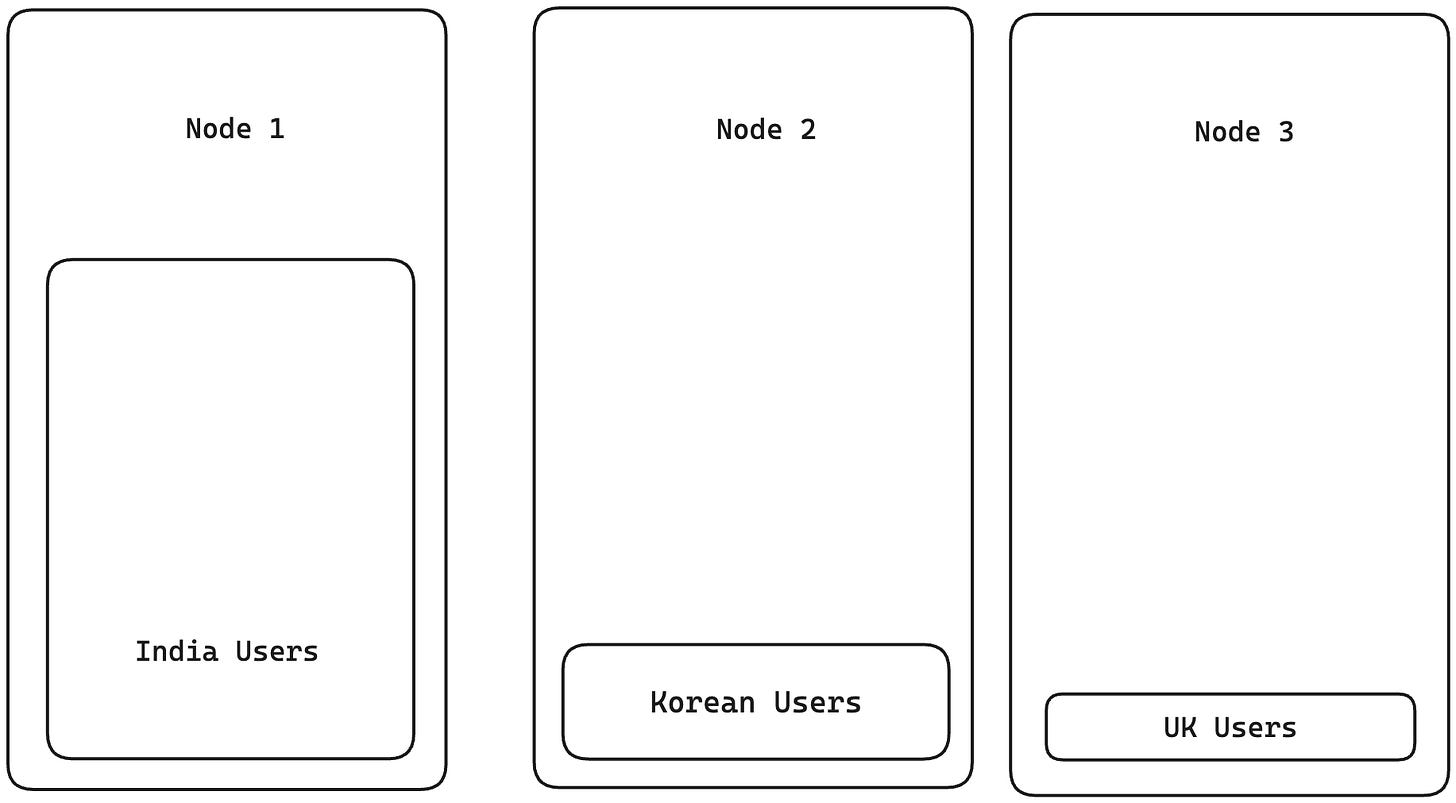
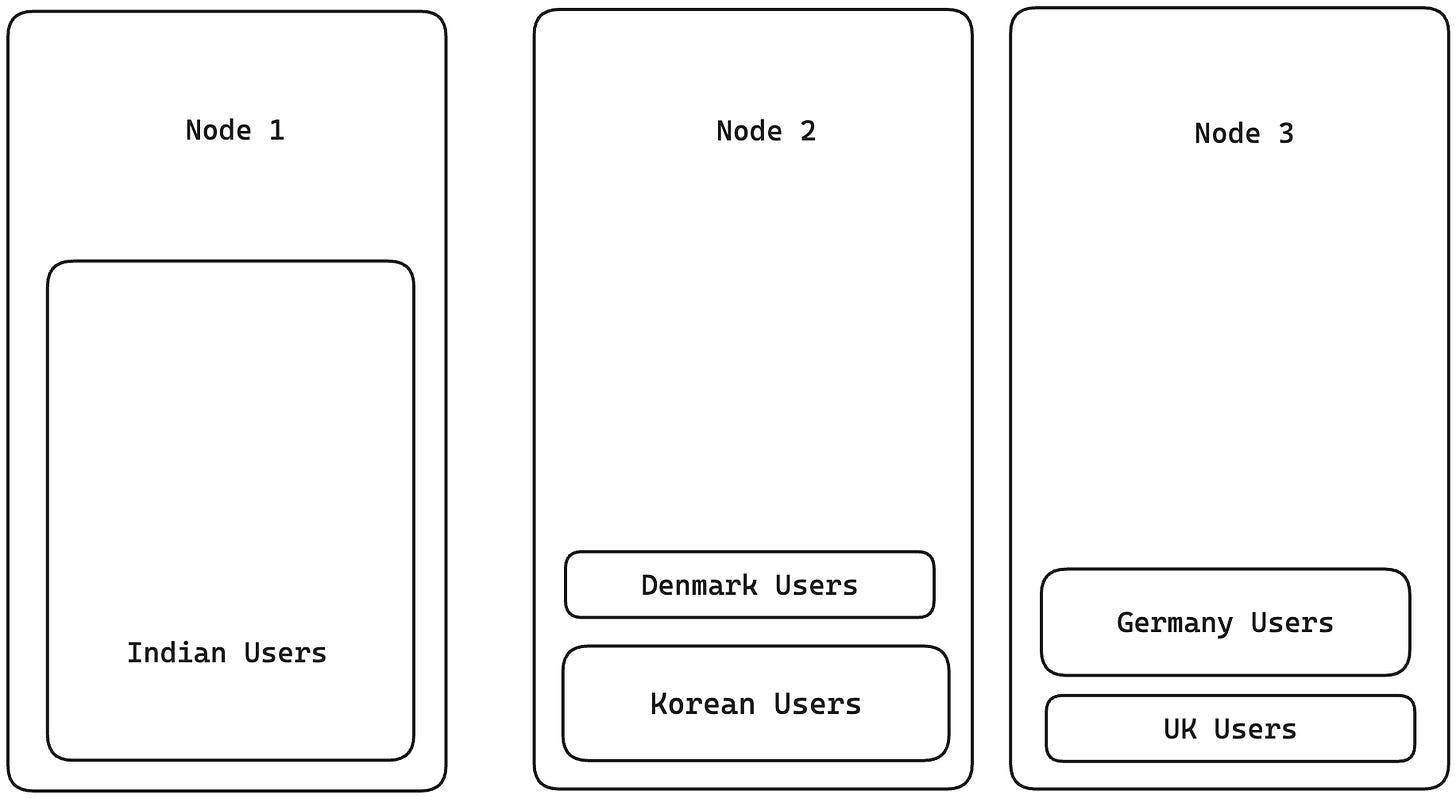
A better approach to partitioning is based on a particular key. For example, say we have a list of people with their names and country of origin. We could partition the list by country of origin. All people from India could be in one partition, all the people from Korea in another, etc. This approach will help us to easily find the node that has a particular person by matching them with the country of origin. The issue with this approach, though, is that it’s prone to skewness and hotspots. Which means that if 80% of people in the data are from India, they will all end up in one node, and the rest of 20% will be across other nodes. So the majority of the system load might be taken up by just one node, which is not desirable. Also, a condition for this approach to succeed is that the value of this attribute should have high cardinality. i.e If there are people only from 4 countries and there are 10 nodes, the data will be stored on only 4 nodes. The other 6 nodes will not have any records assigned to them.
Hash Partitioning
In the above example, we partitioned the database by country. In such cases, there might be a large number of partitions created and only a few nodes. i.e 195 partitions (nodes), 3 nodes. Now, we could store multiple partitions on one node, but how can we find the data when there is a query? The solution to this is a hash-based partitioning scheme. In hash-based partitioning, we insert the key into a hash function, which spits out the node number that the record should go to. For example, if we partition by country, and we have 3 nodes, then India might be assigned to node 1, Korea to node 2, the UK to 3, Denmark to 2, and Germany to 1, and so on. When there is a query, we can use the same hash function to find which node the data lives on.
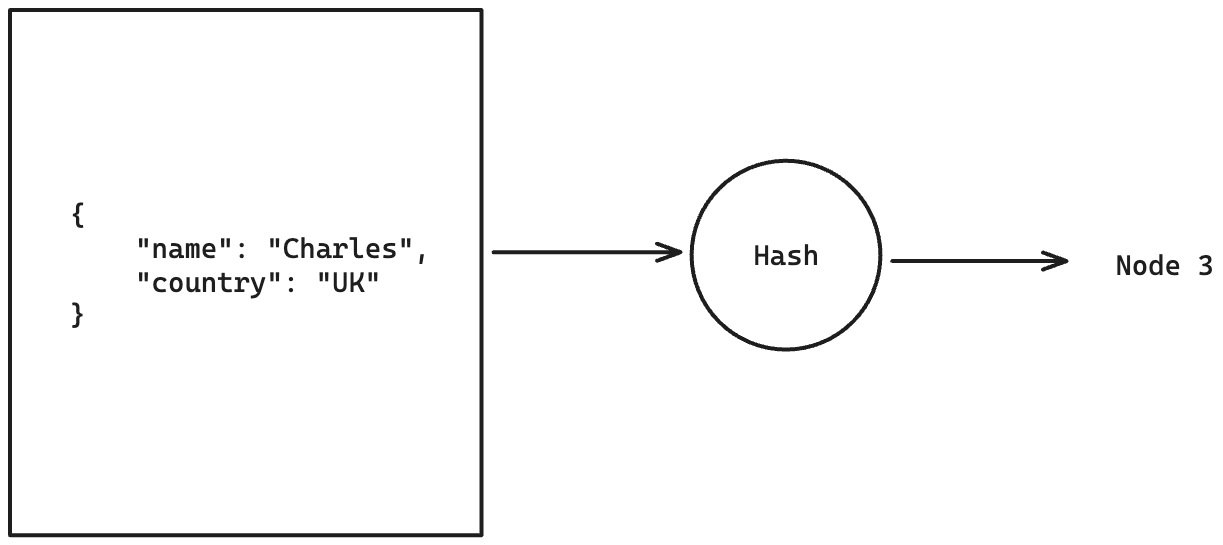
Using a decent hashing function, we could distribute the records pretty uniformly across the nodes. The only drawback of hash partitioning is that it destroys ordering. Given that the records are mapped to nodes in a pseudo-random order, if we make a query like fetch the last 100 records of a user, then the database engine will have to fetch the last 100 records from each node, sort them out in the main node, and then pick the latest 100, which is very inefficient.
Range Partitioning
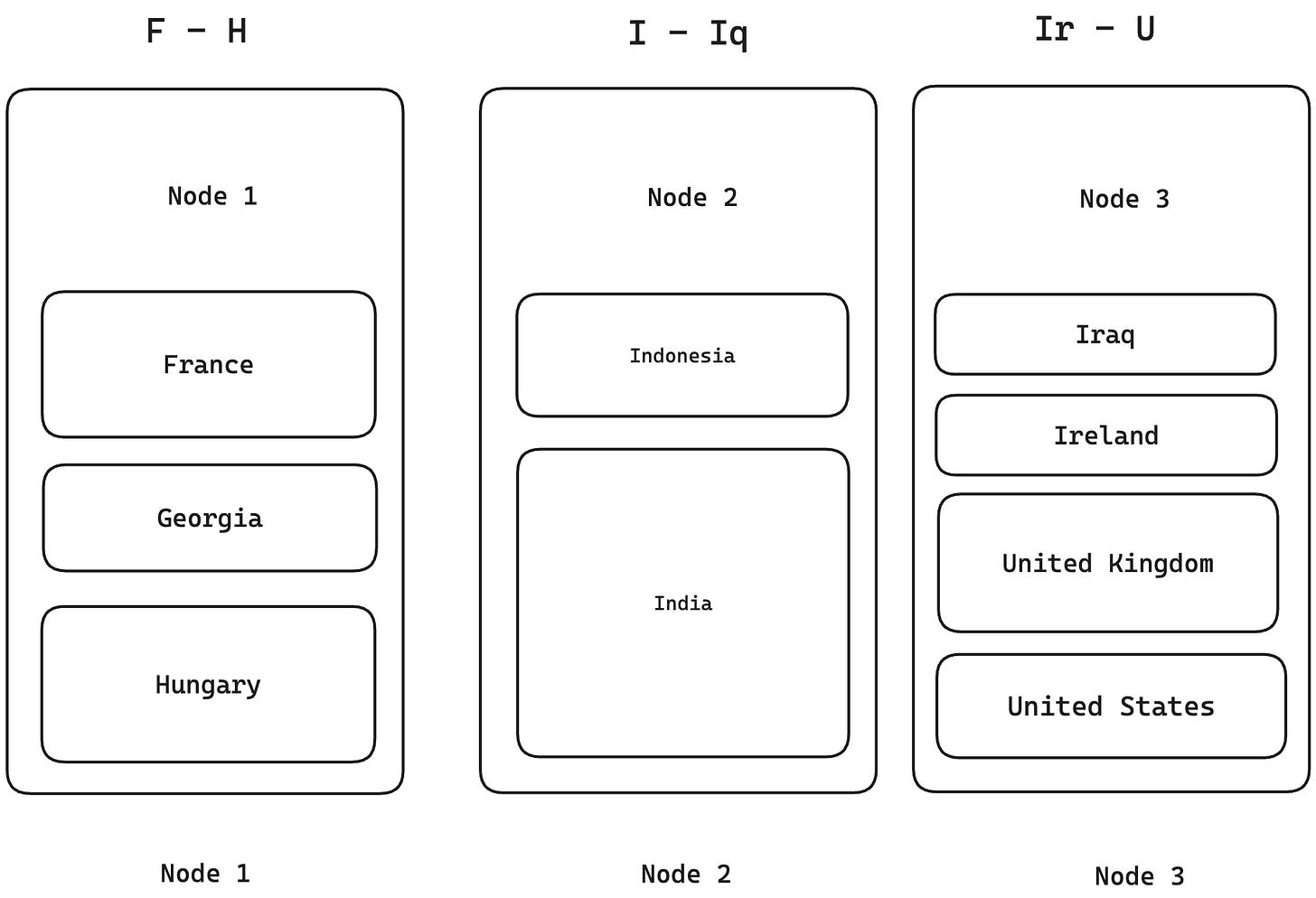
In the range-based partitioning, the data is divided by a key range. For example, if we have a list of users and we range partition by country name, then all the names starting from A-C might be put in node 1, D-F in another, G-K in another. This way, we would know which nodes contain which ranges of the key, and we can fetch and write to these nodes accordingly. An advantage of this method is that if one key dominates the dataset, then it can be split into a smaller group and pushed to another node. For examples if the I names are a large set, you can split it as I - Iq, Ir-U into another node. We could also use this to repartition a node in case the data grows too large.
The one issue with range partitioning, however, might arise during writes. For example, i.e in user event activities, if we partition the data by timestamp (i.e., one day in one partition), all the writes for the one day will flow to one node, overloading it, while the others remain idle. Hence, it is very important to choose the right partition keys here.
Composite Key Partitioning
Composite keys comprise of two parts. Partition key and Sort key. One functions at the inter-node level (routing data to the right server) and the other at the intra-node level (organizing data on the disk). Composite Key partitioning helps us solve the issues faced in Hash and Range partitioning by grouping and sorting related data together on one node. For example, for user event activities flowing in, data may first be partitioned by the user and then stored in the nodes. Within those nodes, the data for these users will be grouped and sorted by timestamp.
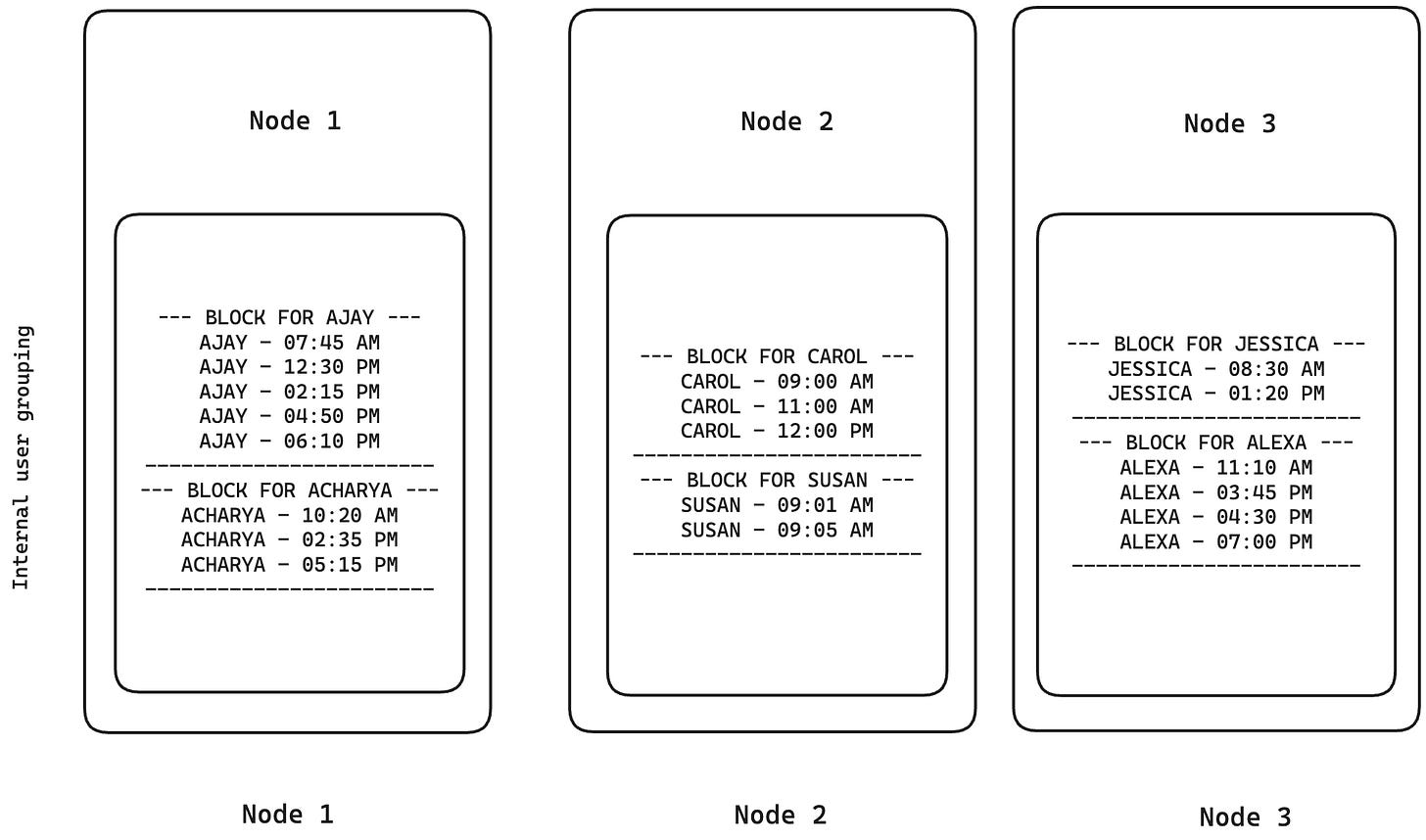
For example, say we have user data that contains name, country, and timestamp. We can have a primary partition key that will partition the data by User. Within these partitions, the data will be grouped by user and sorted using the timestamp field, i.e., Carol’s records will be stored together and sorted by timestamp. During a range query, for example: “All records for Carol from 31st December 2025 between 11.00 AM and 12.00 PM”, the database will find the node by the user name and then fetch all her records between the timestamps of 11.00 AM and 12.00 PM as they are already sorted and stored together.
Measurements to do while partitioning
When choosing partitioning and indexing schemes, it is important to step back and ask exactly what we are trying to achieve. We need to have a look at the data, the frequency, and the type of read and write queries, what the hotspots are, etc. Once we know this, we can implement a partitioning scheme.
Some factors to keep in mind are:
- For a range query, the best performance can be achieved if the data to be fetched for that query sits in one node in one partition adjacent to each other.
- For multiple read queries, it’s best that they can be distributed across multiple nodes, and each node can serve the requested data without requiring data from other nodes.
- For write queries, it’s best to have each write request hit different nodes so that the load is distributed.
Of course, we cannot have a perfect setup for this, and there will always be a compromise, but it’s best to keep this in mind when designing a system. The type of queries will give you a good idea of how to design the scheme.
