
A Deep Dive into Spark UDFs

What is a Spark UDF?
Anyone who has worked with PySpark has probably come across User Defined Functions. UDF’s are functions in PySpark which can be used to do very specific custom tasks that might be difficult or not possible in native PySpark. Here’s a simple example:
This is a simple dataframe with username and date of birth:
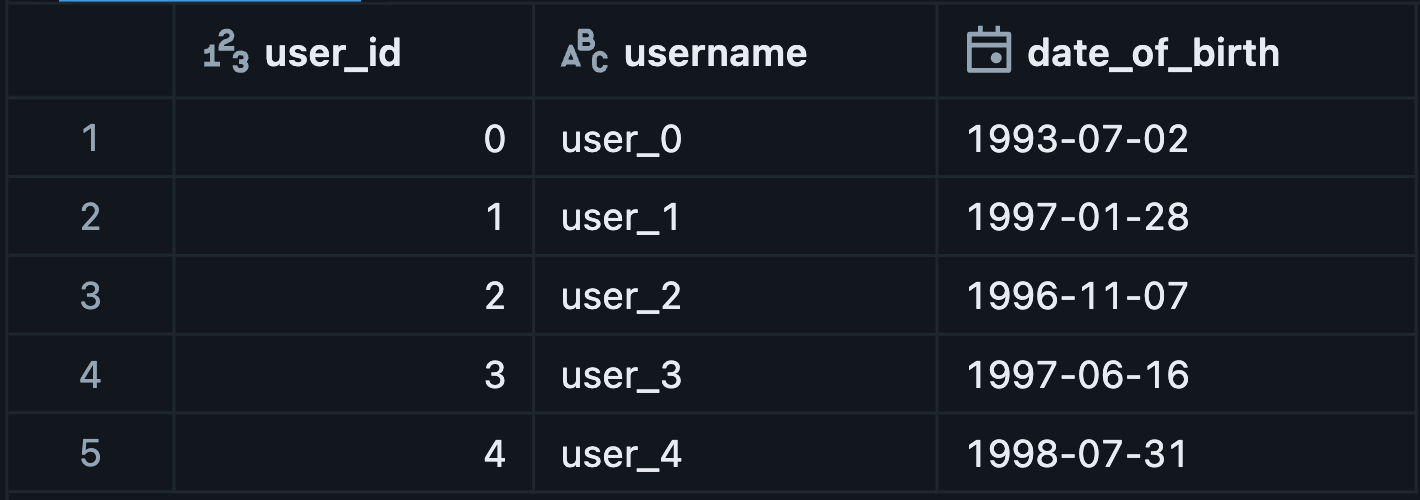
We will create a Python UDF here to infer the users current age via using this date of birth.
from pyspark.sql.functions import udf
import datetime as dt
from dateutil import relativedelta as rd
from pyspark.sql.types import IntegerType
@udf(IntegerType())
def infer_age_udf(date_of_birth):
try:
return rd.relativedelta(dt.datetime.now(), date_of_birth).years
except Exception:
return None
users_df_udf = users_df.withColumn("age", infer_age_udf(col("date_of_birth")))This is the end result:
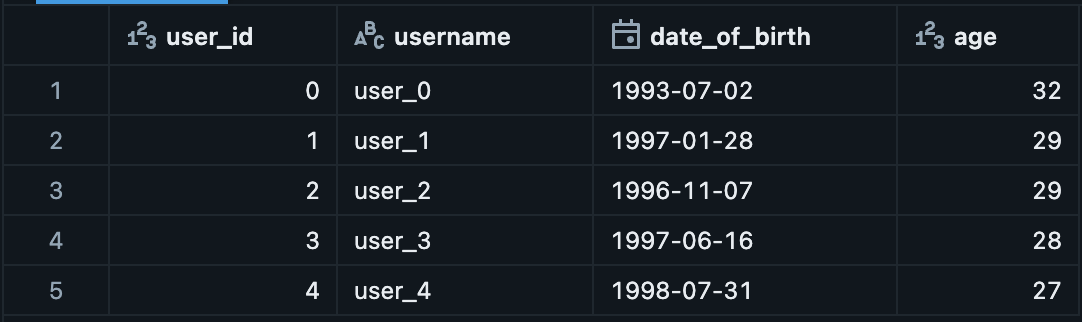
This a common UDF implementation we often see in PySpark. UDF’ s however comes with a hidden underlying cost. Most new developers assume that UDF’s are just a quick way to implement Python logic and get something done quickly. PySpark usually gives this impression that it’s all within the Python ecosystem, so it runs one and the same. But that is an assumption far from the truth.
So what happens when you use a UDF in PySpark?
Contrary to our beliefs, the PySpark application does not really run Python. Sure it has a Python syntax, but internally, it is just a Python wrapper communicating with a Scala application running on the JVM. When we call a built-in PySpark function, we are ultimately calling a highly optimized Scala function.
Scala is a compiled language that runs on the JVM. Because Spark has full control over this native code, its Catalyst Optimizer can inspect and optimize it to a massive extent. This is what makes Spark so fast.
The exception to this rule is UDFs. When we create a custom Python UDF, it does not automatically translate into Scala. Spark has no Scala equivalent for your custom Python logic. To run this code, the Spark Executor JVM has to exclusively spin up a separate Python worker process on each node.
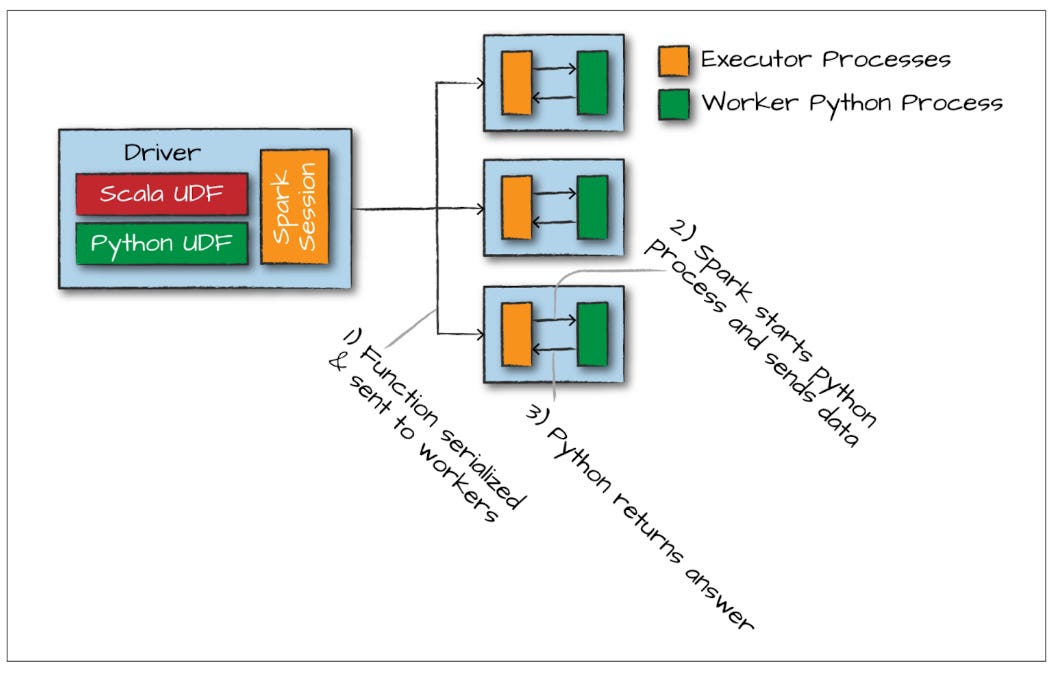
The major overhead here is data serialization. To pass data out of the JVM and into the Python worker, Spark has to serialize (pickle) the data. The Python worker executes your code, and then the results must be serialized again and sent back to the JVM.
Furthermore, because this execution happens inside a black-box Python process outside the JVM, Spark's Catalyst Optimizer cannot inspect or optimize your code. You are completely at the mercy of the Python worker.
So what can we do about it?
Native Spark (The best approach)
In most instances, UDF’s can be completely avoided by using Spark native functions. String manipulations, mathematical calculations, dictionary accessors can all be implemented in PySpark itself. The following code will give us the exact same results without touching a UDF, utilizing native PySpark code but giving us a 13x speedup:
from pyspark.sql.functions import col, current_date, months_between, floor
users_df_native = users_df.withColumn(
"age",
floor(months_between(current_date(), col("date_of_birth")) / 12)
)Pandas UDF (Vectorized operations)
If you must use Python, you can speed up processing by using Pandas UDFs. Pandas UDFs utilize Apache Arrow which does not require data serialization for copying data and leverages vectorized operations which speed up processing.
from pyspark.sql.functions import pandas_udf
from pyspark.sql.types import IntegerType
import json
import pandas as pd
import datetime as dt
@pandas_udf(IntegerType())
def infer_age_pdf(dob: pd.Series) -> pd.Series:
today = dt.datetime.now()
dob = pd.to_datetime(dob)
age = (today.year - dob.dt.year)
birthday_past = (today.month < dob.dt.month) | ((today.month == dob.dt.month) & (today.day < dob.dt.day))
# Calculate age and subtract 1 if the birthday hasn't occurred yet
return age - birthday_past.astype(int)
users_df_pdf = users_df.withColumn("age", infer_age_pdf(col("date_of_birth")))Scala UDF
Another option is to write your UDF in Scala. These are extremely performant and fit natively into the Spark ecosystem. The JVM executes them directly, meaning there is zero Python serialization overhead.
%scala
import org.apache.spark.sql.api.java.UDF1
import java.time.LocalDate
import java.time.Period
import java.sql.Date
class InferAge extends UDF1[java.sql.Date, Integer] {
def call(dob: java.sql.Date): Integer = {
if (dob != null) {
val birthDate = dob.toLocalDate
val today = LocalDate.now()
val age = Period.between(birthDate, today).getYears
age
} else null
}
}
spark.udf.register("infer_age_scala", new InferAge(), org.apache.spark.sql.types.IntegerType)from pyspark.sql.functions import expr
users_df_scala = users_df.withColumn("age", expr("infer_age_scala(date_of_birth)"))Benchmarks
Here are the benchmarks for this Dataframe of 1,000,000 rows. You can see the massive difference in performance among these methods. The native Scala options are extremely fast, followed by the vectorized pandas UDF implementation. The Python UDF is around 13x slower due to the Python serialization and execution overhead.
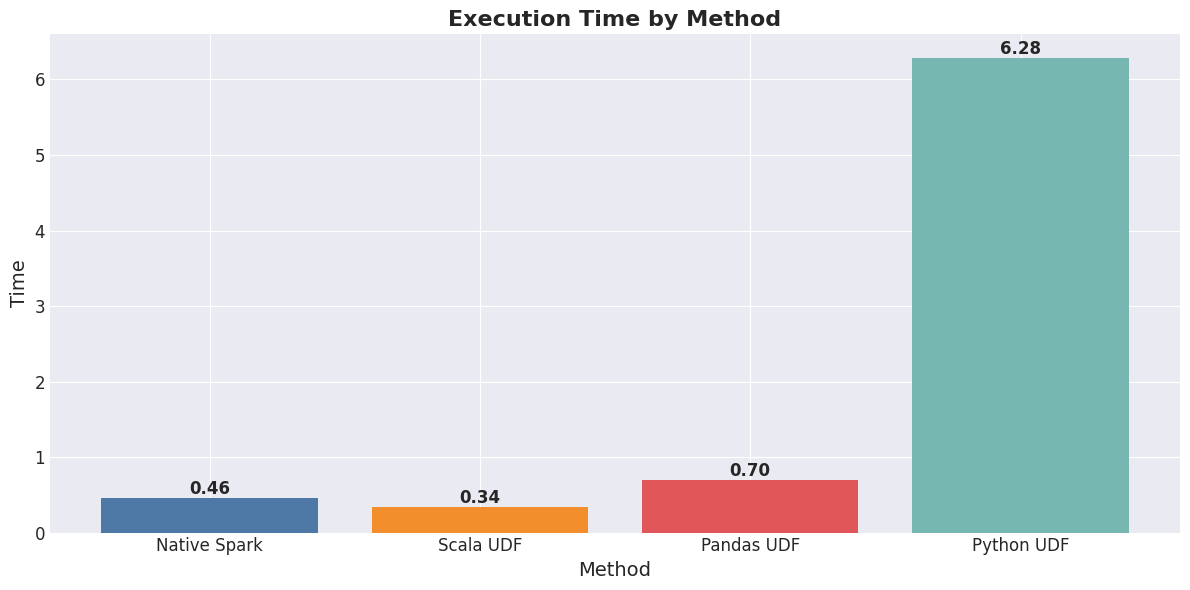
These Python UDF alternatives will work most of the time. There are a few exceptions like using Python machine learning libraries which don’t have Scala/Java equivalents. Those are acceptable cases where we would need Python UDF’s to get the job done.
When writing code, ensure you keep these things in mind as and when dealing with your data. These tiny optimization make a huge difference during heavy compute operations.
If you’d like to have a tool to ensure such issues are highlighted in your code, you can use CatalystOps within your VS code.
Thanks for reading! Subscribe for free to receive new posts and support my work.
